
What Is Automated Citation Context Extraction?
Automated citation context extraction uses AI to analyze the text surrounding citations in academic papers. This process identifies the "context" or purpose behind a citation - whether it supports, contrasts, or simply mentions prior work. Unlike traditional citation metrics that focus on raw counts, this approach provides deeper insights into how research is referenced.
Key Points:
- Purpose: Understand why a citation is used (e.g., support, critique, or background).
- Process: Extract text around citations, classify intent using machine learning, and handle implicit references (e.g., "this study").
- Technologies: Early methods relied on Support Vector Machines (SVM). Recent advances use deep learning models like Attention Models and BERT-based architectures for greater accuracy.
- Applications: Speeds up literature reviews, improves research analysis, and helps tools like Sourcely suggest relevant sources for academic writing.
- Challenges: Struggles with multi-sentence citations, implicit references, and variations across academic disciplines.
By early 2026, tools like scite and Sourcely have classified billions of citations, transforming how researchers evaluate and write about scientific work.
How Automated Citation Context Extraction Works
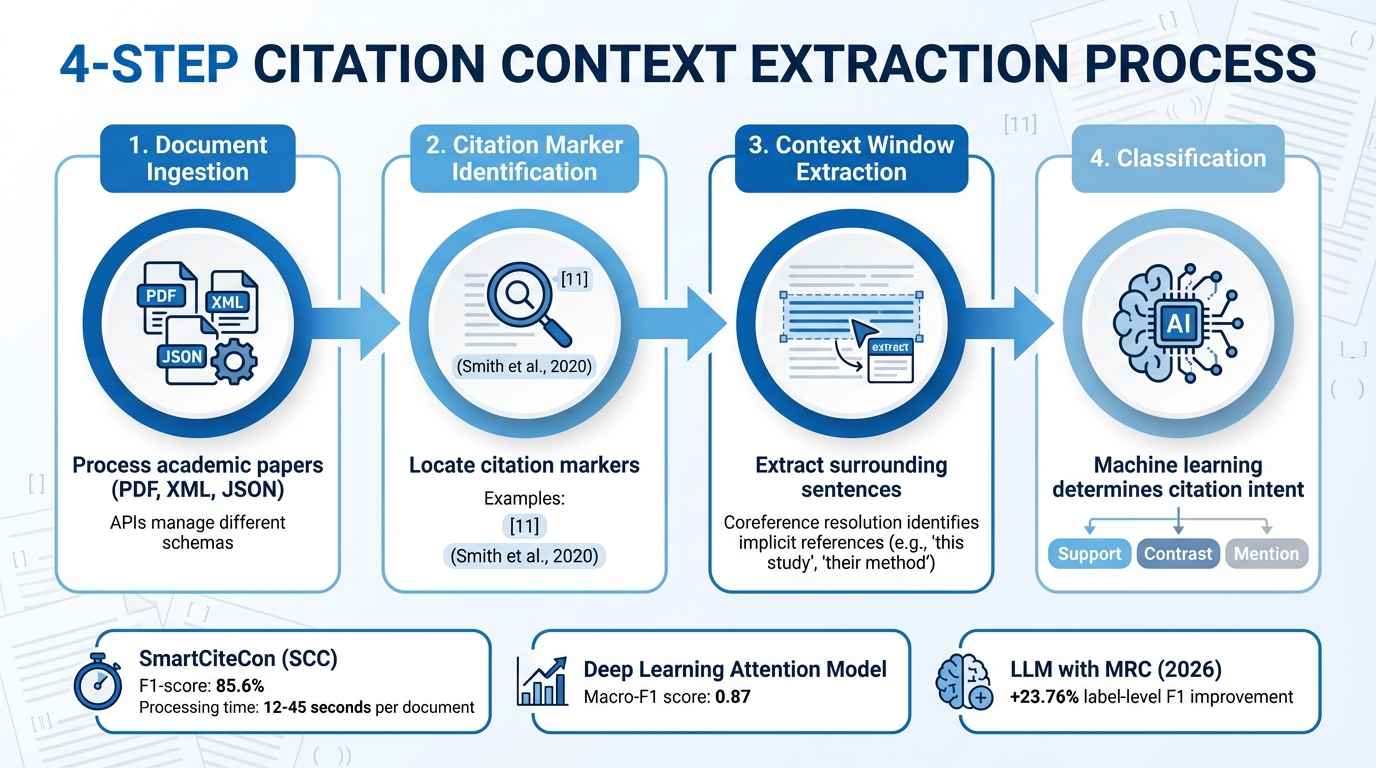
How Automated Citation Context Extraction Works: 4-Step Process
Steps in Citation Context Extraction
The process of extracting citation context begins with document ingestion, where academic papers in formats like PDF, XML, or JSON are processed. APIs are used to manage different schemas, ensuring compatibility. After parsing the document, the system identifies citation markers such as "" or "Smith et al., 2020" within the text.
Once these markers are located, the system extracts a context window, typically encompassing the sentences surrounding the citation. This step captures the relevant context around the reference. More advanced tools go a step further by employing coreference resolution, which helps identify implicit citation contexts. For example, when subsequent sentences mention "this study", "their method", or "the authors", the system links these references back to the original citation.
In August 2020, researchers from Wuhan University and Old Dominion University introduced SmartCiteCon (SCC), a Java API designed to extract both explicit and implicit citation contexts. When tested on the CORD19 dataset, SCC successfully extracted 11.8 million citation context sentences from roughly 33,300 PMC papers. The time required to process a single document ranged from 12 to 45 seconds, depending on the file format.
"SmartCiteCon (SCC)... is built on a Support Vector Machine (SVM) model trained on a set of 7,058 manually annotated citation context sentences, curated from 34,000 papers in the ACL Anthology." - Chenrui Gao et al., Wuhan University
The final stage involves feature engineering and classification. Machine learning models analyze the extracted citation contexts to determine their intent - whether they support, contrast, or simply mention the cited work. To handle large datasets efficiently, these systems often use parallel processing with multithreaded cores, enabling batch document processing. These methods form the backbone for more advanced computational techniques explored in subsequent sections.
Technologies and Algorithms Used
Modern citation context extraction tools build on this foundation by incorporating advanced algorithms and machine learning techniques. Initially, systems relied on Support Vector Machines (SVM) with manually designed features. For example, SmartCiteCon achieved an F1-score of 85.6% using an SVM model trained on 19 specific features.
However, recent advancements have shifted toward deep learning architectures, which deliver improved performance. Attention Models, in particular, have shown better results compared to older approaches like Conditional Random Fields (CRF) and dependency parsing. In May 2024, researchers Dilawar Khan and Iftikhar Ahmed developed a deep learning Attention Model trained on 100 papers from the NLP and Computational Linguistics fields. Their system achieved a macro-F1 score of 0.87, surpassing traditional fixed-window methods.
"Precise reference text extraction from citation contexts (CCs) is important in computational linguistics and information retrieval applications." - Dilawar Khan, Department of Computer Science, University of Engineering and Technology
The latest developments integrate Large Language Models (LLMs) with Machine Reading Comprehension (MRC) for even greater accuracy. In January 2026, researchers at the National Science Library, Chinese Academy of Science, introduced a tool-augmented LLM workflow. This method improved the label-level F1-score by 23.76% and the entity-level F1-score by 31.92% compared to the W2NER model. These systems also utilize BERT-based architectures and Graph Convolutional Networks to classify citation intent and map relationships between citing and cited works.
Benefits and Uses of Citation Context Extraction
Improving Literature Reviews and Research Efficiency
Automated citation context extraction has revolutionized the way researchers approach literature reviews. Tasks that once took hours can now be completed in mere seconds. For instance, analyzing a document manually might take around an hour, but with automated workflows, the same task can be done in just 15 seconds.
But the advantages go beyond speed. Unlike raw citation counts that simply tally mentions, citation context extraction dives deeper, uncovering the true role of each citation. It distinguishes whether a citation offers supporting evidence, presents a contrasting perspective, or is merely a passing reference. For example, the scite platform has analyzed over 25 million full-text articles, building a database of more than 880 million classified citation statements.
"Citation indices help measure the interconnections between scientific papers but fall short because they fail to communicate contextual information about a citation."
– Josh M. Nicholson, CEO, scite
This approach doesn't just save time - it transforms how researchers interpret citations. By providing a clearer picture of citation roles, it helps identify research gaps and prevents redundant efforts. Automated workflows also prove remarkably reliable, matching manual extraction results 76% of the time. Plus, they can handle the messy realities of unstructured PDFs, including spelling inconsistencies and formatting issues.
Simplifying Academic Writing with Sourcely
The efficiency gained from citation context extraction also makes academic writing a smoother process. Tools like Sourcely use this technology to help researchers quickly locate and incorporate relevant sources into their work. Instead of manually searching through databases or skimming countless abstracts, users can paste entire essays or specific sections into the platform. Sourcely’s AI then analyzes the text, identifies areas needing citations, and suggests relevant sources from a database of over 200 million research papers.
Sourcely doesn’t stop at finding sources. It provides concise summaries of the material and allows instant export of references in the required formats. Advanced filters let users narrow results by factors like publication year, authorship, or citation intent - whether they’re looking for evidence to support a claim or challenge it. The "Chat with Sources" feature even enables researchers to ask specific questions and get targeted insights from academic papers without having to read them in full.
For those curious about costs, Sourcely offers a free plan with basic features. Paid plans start at $17 per month or $167 per year, with premium options unlocking unlimited deep searches and the ability to analyze entire papers.
sbb-itb-f7d34da
Challenges and Limitations of Citation Context Extraction
Handling Complex and Non-Contiguous Contexts
Automated tools for extracting citation contexts often work well with straightforward cases but struggle when citations span multiple sentences or even paragraphs. Most systems are built on the assumption that citations fit neatly within a single sentence. However, academic writing frequently involves discussions that extend over entire sections, making this assumption unrealistic.
Another common issue is the handling of implicit citations. These occur when authors continue discussing a previously cited work without restating the formal citation marker. This becomes even trickier when the relevant context is scattered throughout the document.
"Traditional frameworks for CCA [Citation Context Analysis] have largely relied on overly-simplistic assumptions of how authors cite, which ignore several important phenomena. For instance, scholarly papers often contain rich discussions of cited work that span multiple sentences and express multiple intents concurrently."
– Anne Lauscher, Researcher, MultiCite Project
In July 2021, Anne Lauscher and Kyle Lo led a research team to develop the MultiCite dataset, designed to address these challenges. This dataset supports document-level context extraction and accounts for multi-sentence discussions, moving beyond fixed-width classification approaches. However, a significant hurdle remains: managing concurrent intents. For instance, a single citation might simultaneously support a method while critiquing a result. Single-label classification systems struggle with such complexities, complicating automated extraction and potentially affecting the reliability of derived research insights.
Differences Across Academic Fields
The challenges don’t end with complex citation structures. Variations in academic conventions across disciplines further complicate citation context extraction. Tools trained on one field often falter when applied to another due to differences in writing styles and citation practices. For instance, models developed using Natural Language Processing papers might perform poorly when applied to biomedical or legal research [7,9].
Each academic discipline has its own citation norms, creating unique obstacles for extraction tools. Humanities scholars using MLA style often emphasize page numbers for textual analysis, while social scientists following APA style prioritize publication years to highlight research relevance. Meanwhile, fields like law and history rely heavily on footnotes or endnotes (e.g., Chicago Notes or Bluebook) to cite sources such as court cases or government records, which don’t fit neatly into parenthetical references. These variations require extraction tools to look beyond the main body text, a task they are often ill-equipped to handle.
In May 2024, Dilawar Khan and Iftikhar Ahmed from the University of Engineering and Technology in Peshawar explored this limitation. They implemented a deep learning Attention Model on a dataset of 100 papers from Natural Language Processing and Computational Linguistics. While their model achieved a macro-F1 score of 0.87, its performance could drop significantly when applied to disciplines with different citation patterns and linguistic structures. This underscores the importance of tailoring extraction systems to the specific needs of each academic field.
Conclusion
Automated citation context extraction is changing the way researchers assess academic literature. Instead of relying solely on raw citation counts, modern tools now examine the text surrounding a citation to determine its role - whether it supports findings, offers contrasting evidence, or is simply a mention. This contextual approach provides a clearer and more nuanced understanding of a paper's influence and reliability within the scientific community.
The technology has come a long way. By early 2026, platforms like scite have analyzed over 200 million sources and classified more than 1.5 billion citation statements. Advances in Machine Reading Comprehension and Large Language Models have boosted extraction accuracy by 23.76% compared to earlier methods. These developments not only improve current research workflows but also pave the way for future advancements.
The Future of Research with Automated Tools
With these advancements, the next generation of tools promises to make research even more efficient and effective. Automated citation tools are already saving researchers countless hours while improving the quality of their work. Sourcely is a prime example, offering access to over 200 million research papers and features that extend beyond basic keyword searches. Users can paste essay drafts directly into the platform, where the AI identifies citation gaps and suggests relevant academic sources. Sourcely's scalable plans cater to everyone from students to seasoned academics.
Looking ahead, research workflows will likely see even more sophisticated tools. Conversational AI interfaces could allow researchers to explore papers naturally, while grounded AI systems will back claims with verifiable, peer-reviewed evidence. As Mark Mikkelsen, Ph.D., from The Johns Hopkins University School of Medicine, puts it:
"It's never been easier to place a scientific paper in the context of the wider literature".
This statement underscores the transformative potential of automated citation context extraction - not just as a time-saver, but as a way to fundamentally improve how we discover, evaluate, and expand scientific knowledge.
FAQs
How does automated citation context extraction enhance literature reviews?
Automated citation context extraction simplifies the process of conducting literature reviews by pinpointing the specific context in which sources are cited. This makes it easier to grasp how each source connects to the research topic, offering clear and concise summaries that highlight the most relevant studies.
By cutting down the time spent analyzing citations, this technology ensures that important insights from referenced works are seamlessly incorporated into academic writing. The result? Research that's more thorough and better supported by the most relevant studies.
What are the main challenges of extracting citation contexts in different academic fields?
Citation context extraction comes with its fair share of hurdles, especially given the variety in how citations are used and presented across academic disciplines. For example, some fields favor clear and direct citation sentences, while others weave citations subtly into the narrative. This subtlety can make it tricky for automated tools to spot and interpret citations correctly, often leading to missed or irrelevant details.
Another layer of complexity comes from the diverse formats and structures of academic documents - ranging from PDFs to XMLs - that these tools need to navigate. On top of that, varying citation styles and the intricate nature of scientific language add to the challenge. Overcoming these obstacles calls for advanced models that can handle implicit, fragmented, and unconventional citation contexts, ensuring better accuracy and consistency across different fields.
How do advanced AI technologies improve citation context extraction?
Advanced AI technologies, such as BERT and Attention Models, have transformed how citation contexts are analyzed. These tools are designed to grasp the intricate and shifting relationships within text, offering a more accurate understanding of the context surrounding citations. This means they can pinpoint referenced materials with precision and evaluate their relevance effectively.
With these advancements, researchers can better interpret how sources are utilized in academic work. This not only simplifies the process of categorizing citation types but also clarifies their intended purpose. The result? Smoother research workflows and more systematically arranged references.
