
Latency in Federated Search: Research Insights
Latency in federated search systems can significantly impact performance, user experience, and decision-making. Here’s what you need to know upfront:
- What is Federated Search? It queries multiple databases simultaneously, consolidating results into one interface without moving data.
- Why Latency Matters: High latency slows response times, leading to abandoned searches and incomplete decisions. This is critical in fields like healthcare and e-commerce.
- Main Causes of Latency:
- Network Delays: Physical distance and connectivity issues between data sources.
- Data Source Differences: Varied formats and synchronization issues.
- Indexing & Query Processing: Dependency on each source’s APIs and security checks.
- Optimization Methods:
- Caching: Reduces redundant processing.
- AI Routing: Streamlines queries and improves efficiency.
- Encryption Advances: Balances security and speed.
Key Takeaway: Effective latency management through caching, AI, and better resource handling ensures federated search systems deliver fast, reliable results.
Presto: Optimizing Performance of SQL-on-Anything | Starburst

Main Causes of Federated Search Latency
To improve the performance of federated search systems, it’s essential to understand the factors that contribute to delays. Research highlights several key causes of latency, each posing unique challenges for system designers.
Network Delays and Parallel Query Processing
Network connectivity is one of the biggest culprits behind federated search latency. When systems are distributed across various geographic locations, delays and connectivity issues can severely bottleneck performance.
This is especially problematic in geo-distributed setups where data sources are spread across multiple regions. Studies show that high latency and intermittent network failures can cause system stability to drop to as low as 83–92% in poorly optimized configurations. However, with dynamic adjustments, stability can improve to nearly 99.5–100%.
Physical distance between data sources and the query engine also plays a critical role. The farther apart they are, the longer it takes to retrieve and process information. This delay becomes even more pronounced when databases are located on different continents or across multiple cloud regions.
Although federated queries reduce data movement and network traffic compared to traditional methods, they still lag behind querying local storage due to inherent network delays. To counter this, experts suggest limiting the amount of data retrieved from remote sources and applying query filters to reduce scan size. Monitoring the ratio of scanned-to-returned bytes can also help identify inefficient queries.
Beyond network issues, differences in data source formats add another layer of complexity to federated search performance.
Data Source Differences and Synchronization Issues
Varied data formats and synchronization requirements further contribute to latency. Federated search systems often deal with heterogeneous data sources, each with its own structure and format. These differences necessitate preprocessing steps, which add delays before unified results can be displayed.
For example, data can come in formats ranging from text files to relational databases. Normalizing this data for a unified presentation introduces unavoidable processing time. Synchronization is another significant challenge. Systems relying on index-time merging require constant updates to maintain accuracy across all data sources. However, this approach often sacrifices the freshness of the data, creating a trade-off between speed and up-to-date results.
Real-time querying across multiple sources also slows down response times, particularly for complex searches or when multiple systems are involved. This lag can directly affect user experience - research shows that even a one-second delay in page load time can result in a 7% drop in conversions.
Additionally, inconsistent data quality and duplicate content can complicate relevance and reliability. Managing multiple endpoints and ensuring compatibility with each data source adds further complexity compared to unified search systems.
Indexing and Query Processing Problems
Latency issues don’t stop at network and synchronization challenges - indexing and query processing also play a role. Unlike unified search systems that rely on centralized, pre-indexed data, federated search interacts with each data source’s unique search API and internal indexing.
This dependency introduces constraints, as each source has its own search syntax, filter options, and security permissions. These differences require additional authentication and authorization checks, which lengthen query processing times.
Performance inconsistencies across data sources further exacerbate the issue. For instance, some databases may respond in milliseconds, while others take seconds. Federated systems must wait for the slowest source before presenting complete results. Ranking and relevance management also become tricky, as each source uses its own ranking algorithms. The system must either accept inconsistent rankings or spend extra time normalizing relevance scores.
Security adds yet another layer of complexity. Federated search systems rely on each data source’s security measures, which means additional authentication and authorization checks for every query. This distributed security approach increases overall latency.
To mitigate these challenges, implementing caching mechanisms and streamlining API calls can significantly improve performance. Additionally, using standardized data formats and protocols simplifies integration and reduces processing overhead. These strategies, along with robust caching and standardization, are explored further in the next section.
Research Findings and Optimization Methods
Addressing the challenges in federated search, recent studies have introduced specific techniques to tackle latency while maintaining the benefits of distributed systems. These approaches focus on boosting efficiency without compromising security or functionality.
Caching and Query Optimization Methods
One effective way to cut delays is through caching and query optimization. By caching frequently accessed query results and implementing smart cache invalidation policies, systems can significantly reduce redundant processing. A standout approach, multiplicative caching (MC), enhances computational efficiency in encrypted environments while safeguarding data privacy. These caching strategies also set the stage for integrating smarter query management powered by AI.
AI-Based Source Selection and Routing
AI has proven highly effective in improving source selection and query routing. For instance, the RAGRoute mechanism leverages neural network classifiers to streamline query handling, cutting down queries by 77.5% and reducing communication volume by 76.2%. Impressively, it achieves inference times of just 0.3 ms on an NVIDIA A100 GPU and 0.8 ms on an AMD EPYC CPU, while maintaining high recall rates: 95.3–99.0% for top-10 retrieval and 96.7–98.5% for top-32 retrieval. These results are achieved by using training features like query embeddings and data source centroids. While these advancements optimize query routing, maintaining data integrity remains a critical focus.
Encryption and Resource Management Advances
Recent progress in encryption technologies has shown that robust security can coexist with low latency. Homomorphic encryption (HE) and secure multi-party computation (MPC) are at the forefront, enabling secure operations without sacrificing speed. Notably, single-key homomorphic encryption (SK-MHE) simplifies key management, reducing the complexity and overhead of handling multiple encryption keys.
Trusted execution environments (TEEs), such as SGX enclaves, add another layer of protection by securing queries and documents during processing. When combined with intelligent routing, such as RAGRoute, these methods minimize redundant cross-silo queries by 75%, further cutting down latency. Additionally, FRAG employs IND-CPA–secure homomorphic k-NN encryption, which ensures vector search functionality without exposing raw indexes.
Together, these findings highlight the potential for creating federated search systems that are both efficient and secure, offering a promising path forward for this technology.
Performance Metrics for Federated Search Latency
Evaluating the performance of federated search systems involves using multiple metrics to get a clear picture of how well the system is operating. Because distributed systems are inherently complex, it’s crucial to use a combination of benchmarks and measurements to gauge both speed and quality. Striking the right balance between these two factors is key to understanding system health and efficiency.
Balancing Latency and Search Results Quality
One of the biggest challenges in federated search is achieving a balance between fast response times and accurate results. If too many data sources are included, the relevance of results can drop. On the other hand, limiting sources too much risks missing critical information.
This trade-off is evident in systems like RAGRoute, which uses intelligent source selection to maintain high accuracy while minimizing latency. For instance, RAGRoute achieves recall rates of 95.3% to 99.0% for top-10 retrieval and 96.7% to 98.5% for top-32 retrieval. These metrics highlight how well the system performs in retrieving relevant information without unnecessary delays.
Latency metrics, such as median (50th percentile) and worst-case (99th percentile) response times, are essential for identifying performance consistency and spotting outliers. These measurements ensure that users experience reliable performance, even under varying workloads.
Common Benchmarks and Performance Measures
Standardized benchmarks are essential for evaluating federated search systems. Benchmarks like MIRAGE, MMLU, and FeB4RAG focus on key aspects such as client relevance, privacy, and network efficiency. These tools help set consistent standards for performance evaluation.
Newer frameworks, such as RAGAS, take this a step further by offering metrics tailored specifically to federated RAG pipelines. These metrics address not just response speed but also factors like privacy constraints and network costs, giving a more complete picture of system performance.
| Metric Type | Measurement Focus | Key Applications |
|---|---|---|
| 50th Percentile Latency | Median response time | General performance baseline |
| 99th Percentile Latency | Worst-case scenarios | Service level agreements |
| Query Reduction Rate | Query efficiency | Resource utilization |
| Recall Accuracy | Result completeness | Quality assurance |
In addition to these benchmarks, analyzing latency at the component level helps identify bottlenecks. By measuring delays in embedding computations, retrieval times, and language model inference, developers can target specific areas for optimization as the system scales. Metrics like request rates and subscription notification rates also provide insights into traffic patterns, helping with capacity planning and resource management.
Real-world examples show how these metrics translate into practical benefits. For instance, in healthcare, federated RAG systems have reduced diagnosis times by 20%. By integrating real-time patient data with medical literature, clinicians can quickly access up-to-date insights alongside patient histories, improving decision-making.
The field of federated search continues to evolve with new benchmarks addressing emerging challenges. Recent innovations include NVIDIA's C-FedRAG, a TEE-based confidential QA system introduced in 2024, and Adobe's MKP-QA, which focuses on multilingual enterprise retrieval, launched in 2025. These advancements highlight the growing sophistication of federated search applications across various industries.
Hybrid retrieval systems are particularly promising, offering the potential to reduce latency by up to 50% while maintaining high levels of accuracy.
sbb-itb-f7d34da
Tools and Applications for Academic Research
Drawing from latency research and optimization techniques, these examples highlight how academic researchers tackle federated search latency challenges. Practical implementations showcase strategies that manage latency effectively while ensuring high-quality outcomes in academic research.
Case Studies of Federated Search Systems
Examples from various fields shed light on how federated search systems address latency while maintaining performance. Academic institutions, for instance, have developed advanced federated search platforms tailored to interdisciplinary research needs. These systems often use intelligent caching to locally store frequently accessed research papers and citation data, significantly cutting down the time spent on repetitive external queries. Other approaches include utilizing CDNs and centralized indexing to further enhance speed and efficiency .
The evolution of federated search systems points to a growing preference for hybrid models. These combine the immediacy of real-time querying with the efficiency of pre-indexed content. Many modern systems integrate direct API access to provide real-time results while addressing common challenges like permission restrictions and scalability issues. Such innovations pave the way for specialized tools that simplify the process of finding academic literature.
Using Sourcely for Efficient Literature Discovery
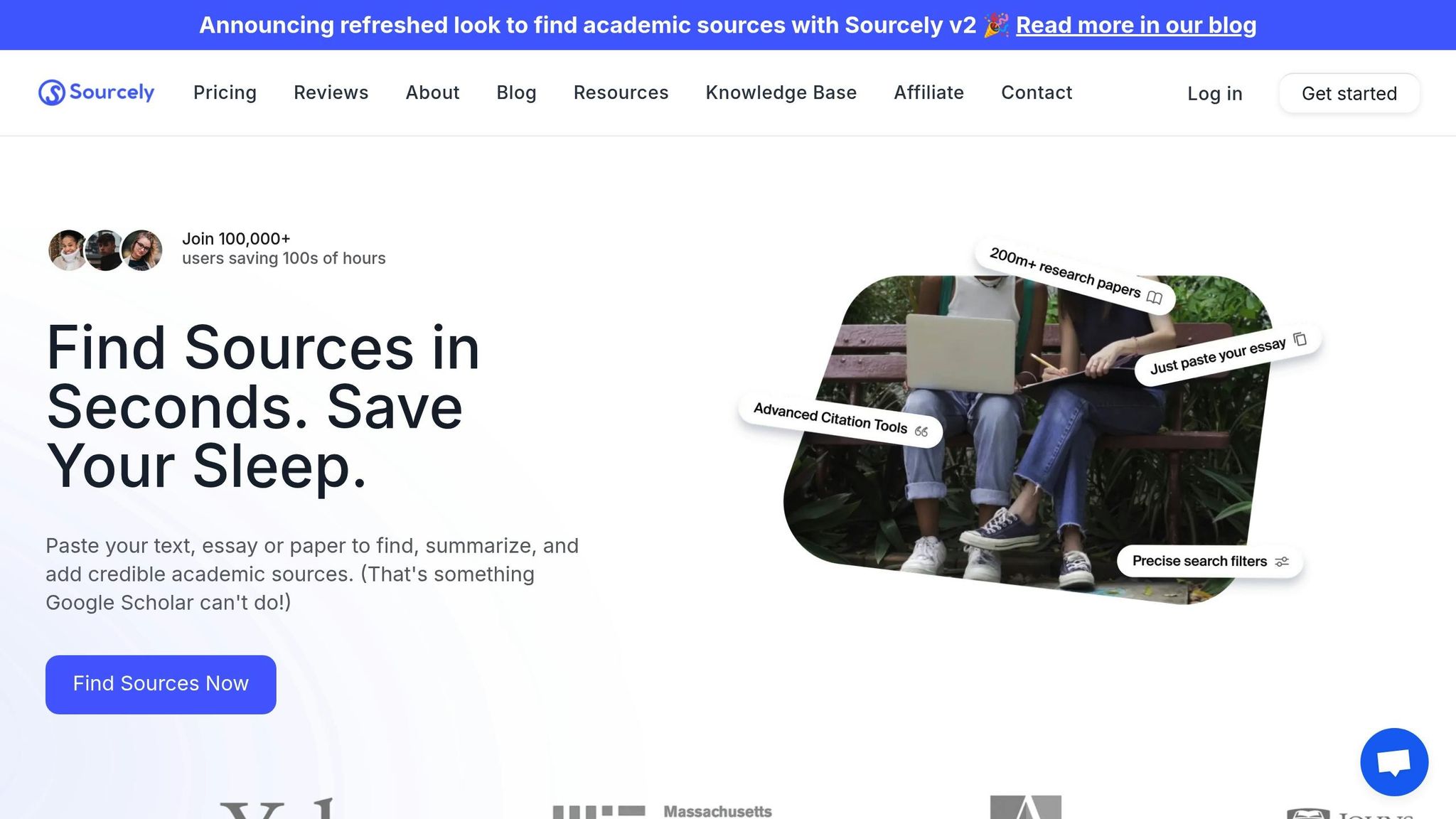
Building on these advancements, Sourcely offers an AI-powered platform designed to tackle the complexities of federated search in academic research. With access to over 200 million papers and a community of more than 100,000 researchers, Sourcely navigates distributed academic databases with ease.
One standout feature of Sourcely is its ability to process entire paragraphs or research notes, moving beyond the limitations of basic keyword searches. Mushtaq Bilal, PhD, a postdoctoral researcher at the University of Southern Denmark's Hans Christian Andersen Center, highlights this capability:
"One of the limitations of databases like Google Scholar is that they let you search using only keywords. But what if you want to search using whole paragraphs or your notes? Sourcely is an AI-powered app that will let you do that."
This functionality not only saves time spent refining queries but also reduces redundant searches. Sourcely further enhances the user experience with advanced filtering options, allowing researchers to refine results by publication year, authorship, and relevance.
Sourcely also stands out for its flexibility and affordability. It offers free PDF downloads for many sources, generates reliable summaries, and supports citation exports in multiple formats. These features help researchers cut down on administrative tasks, enabling them to focus on analysis and writing. By addressing latency challenges and simplifying the research process, Sourcely demonstrates how technology can revolutionize academic literature discovery.
Conclusion
Reducing latency in federated search demands a combination of innovative approaches and practical execution. Studies have shown that addressing challenges like network delays, data synchronization, and inefficient query processing is critical to improving performance.
Take RAGRoute, for instance - its AI-powered source selection method slashed total queries by 77.5%. Similarly, fog computing has been shown to cut latency by 40%. These examples demonstrate how smarter routing and better resource management can significantly boost efficiency without compromising the quality of search results.
Hybrid models also play a key role by blending real-time data with pre-indexed content, offering a balance between speed and accuracy. Organizations should carefully assess their specific needs, such as how often their data updates or whether real-time results are essential, before deciding on the right federated search strategy.
These advancements are particularly beneficial for academic research. AI-driven platforms like Sourcely are transforming how researchers discover literature. As mentioned earlier, Sourcely processes entire paragraphs and provides access to over 200 million research papers, tackling the complexities of distributed academic databases head-on. Tools like these are helping to redefine the capabilities of federated search systems.
Looking ahead, the future of federated search lies in intelligent automation and systems that adapt dynamically based on query patterns and available resources. With the growing adoption of edge computing and the continued refinement of AI optimization techniques, federated search will deliver more comprehensive results while keeping latency to a minimum.
FAQs
What makes federated search different from traditional search in terms of data handling and network traffic?
Federated search stands apart from traditional search in the way it handles queries and data. Traditional search operates using a centralized database, where all the data is stored in one place. This setup makes it possible to deliver faster query results and minimizes network traffic since every request is processed through a single, centralized system.
Federated search, on the other hand, works differently. It sends a single query out to multiple independent data sources simultaneously. Each of these sources processes the query on its own, and the results are then combined into a single output. While this method can pull information from a wider variety of sources, it comes with trade-offs. For one, it can increase network traffic and may lead to delays, especially if some data sources are slower to respond. In fact, the total response time often hinges on the slowest source, which adds a layer of complexity to managing the network.
What are effective ways to reduce latency in federated search systems, and how do they improve performance?
Reducing latency in federated search systems is key to creating a smoother, faster, and more responsive user experience. Here are some effective ways to achieve this:
- Cache frequently accessed results: Storing popular search results allows the system to quickly retrieve them without reprocessing the same queries over and over. This can save significant time, especially for high-demand searches.
- Optimize search queries: Simplifying queries and steering clear of overly complex patterns can cut down processing time and make the system more efficient.
- Leverage Content Delivery Networks (CDNs): CDNs store cached responses closer to users, which helps reduce network delays and speeds up the delivery of search results.
- Use load balancers: By spreading traffic across multiple servers, load balancers ensure that no single server becomes overwhelmed, keeping the system running smoothly even during peak usage.
These techniques not only make search results appear faster but also enhance user satisfaction by creating a seamless experience. Additionally, fine-tuning API calls and making smart use of caching can reduce delays when pulling data from multiple sources, ensuring the system remains efficient and responsive.
How do AI and encryption technologies improve the performance and security of federated search systems?
How AI and Encryption Are Shaping Federated Search Systems
Recent developments in AI and encryption technologies have revolutionized federated search systems, making them faster, more precise, and incredibly secure. AI plays a key role in analyzing and retrieving data from multiple sources efficiently, all while maintaining user privacy. For instance, federated learning allows AI models to be trained collaboratively without centralizing the data, which significantly lowers the chances of security breaches.
When it comes to security, cutting-edge encryption techniques like homomorphic encryption take things to the next level. This method enables computations to be performed directly on encrypted data, ensuring that sensitive information remains secure throughout the processing phase. These advancements not only improve how these systems operate but also strengthen user confidence by prioritizing data protection.
