
What Is Automated Source Credibility Scoring?
Automated Source Credibility Scoring uses AI, such as Natural Language Processing (NLP) and Machine Learning (ML), to assess how reliable an information source is. Instead of relying on human experts to manually evaluate sources, these systems analyze factors like bias, tone, citations, and factual accuracy to assign a score or label to a source. This approach is essential for handling the massive amount of information produced daily, especially on social media and by AI-generated content.
Key Points:
- Why It Matters: Manual checks can't keep up with today's content volume. Automation offers faster, scalable evaluations.
- How It Works: AI detects "credibility signals" (e.g., author credentials, bias, factual accuracy) and combines them into a final score.
- Tech Behind It: Tools like Large Language Models (LLMs) and supervised learning analyze text, metadata, and external validations.
- Applications: Helps researchers quickly vet sources, improving efficiency and reducing errors.
By automating credibility scoring, researchers can focus on their analysis while ensuring their sources meet high-quality standards.
How Is AI Changing Source Verification? - The Language Library
Core Principles of Automated Source Credibility Scoring
In response to the growing need for quick and reliable credibility evaluation, automated systems now rely on well-defined principles to measure trustworthiness.
Credibility Signals Detection
Automated tools are designed to identify credibility signals - key indicators that help evaluate the trustworthiness of a source. These signals fall into several categories:
- Academic signals: Includes factors like peer-review status, author credentials, the reputation of the publication venue, and citation metrics.
- Textual signals: Examines elements such as subjectivity, bias, use of persuasion techniques, logical fallacies, and the presence of fact-checked claims.
- Metadata and structural signals: Considers aspects like the age of the website, its corrections policy, and recognition through awards.
Once identified, these signals are extracted and validated systematically.
Modern credibility systems focus heavily on factual accuracy rather than relying solely on hyperlink-based signals. For instance, a Knowledge-Based Trust (KBT) model was applied to analyze 2.8 billion facts from the web, assessing the trustworthiness of 119 million webpages. As Xin Luna Dong, Principal Scientist at Google, explains:
A source that has few false facts is considered to be trustworthy.
The methods used vary depending on the type of signal. Information Extraction (IE) retrieves facts from sources and compares them against established knowledge bases. Meanwhile, Natural Language Processing (NLP) and Large Language Models analyze emotional tone, detect logical fallacies, and flag claims that need fact-checking. Tools like the Wayback Machine help confirm the age of a domain, and Natural Language Inference (NLI) evaluates whether passages support cited statements.
Aggregation and Scoring Mechanisms
After detecting these signals, systems combine them into a single credibility score.
Mean pooling is one method, where statement-level credibility ratings are averaged to produce an overall score for a document. Multiple Linear Regression (MLR) assigns weights to specific "edit actions" based on how they correlate with human-assigned ratings. Additionally, grid search optimization helps determine the best weights for features like factual density and readability.
More advanced techniques include Vanilla Fine-Tuning (VFT), where Large Language Models are trained on specialized datasets to generate continuous reliability scores ranging from 0.1 (completely unreliable) to 1.0 (highly reliable). Another approach, the Iterative Chain of Edits (IterCoE), uses LLMs to reason through necessary improvements before assigning a final score based on the severity and frequency of corrections. The CiteEval-Auto metric has demonstrated a strong alignment with human evaluations.
As Ivan Srba, Senior Researcher at the Kempelen Institute of Intelligent Technologies, explains:
Credibility assessment relies on aggregating diverse credibility signals - small units of information, such as content subjectivity, bias, or a presence of persuasion techniques - into a final credibility label/score.
How Automated Credibility Scoring Works
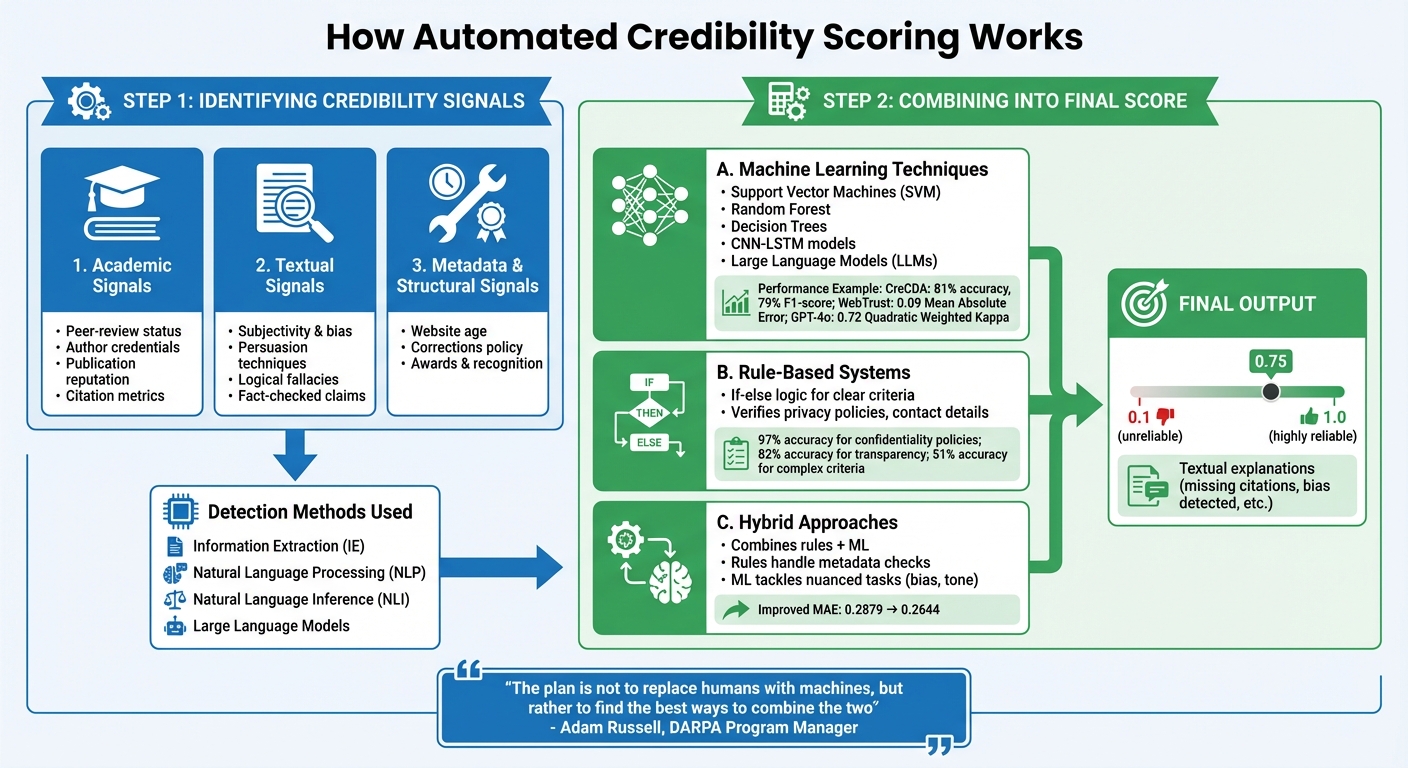
How Automated Source Credibility Scoring Works: A Two-Step Process
Automated credibility scoring works through two main steps: identifying credibility signals and combining them into a final score. These systems rely on machine learning models, rule-based logic, or a mix of both. Let’s break down how these methods work in practice.
Machine Learning Techniques
Machine learning models are trained on datasets labeled by experts to detect credibility patterns. Supervised learning methods such as Support Vector Machines (SVM), Random Forest, and Decision Trees analyze specific features to classify sources as credible or not.
Deep learning takes this further by analyzing text on multiple levels. For instance, CNN-LSTM (Convolutional Neural Network - Long Short-Term Memory) models can identify both local patterns in text and long-term dependencies. In a 2023 study, the CreCDA approach demonstrated an accuracy of 81% and an F1-score of 79% in assessing credible conversations. This was achieved by combining post-level features (like text content and sentiment) with user-level details (such as account age, follower ratios, and verification status).
Large Language Models (LLMs) are the latest advancement in credibility scoring. In 2025, researchers from Tsinghua University and Chandigarh University introduced WebTrust, a system powered by a fine-tuned IBM Granite-1B model. WebTrust evaluated reliability scores on a scale from 0.1 to 1.0, trained on a dataset of over 140,000 articles spanning 21 domains and using 35 reliability labels. The system achieved a Mean Absolute Error of just 0.09. Another study from the same year used GPT-4o for scoring, showing strong alignment with human evaluations, with a Quadratic Weighted Kappa of 0.72 and a Pearson correlation of 0.73.
The technical process behind these models involves converting text into numerical vectors suitable for neural networks. Techniques like Word2Vec and word embeddings map words into low-dimensional spaces, grouping similar meanings close together. This enables models to grasp the semantic context, a crucial factor in assessing credibility.
Rule-Based and Hybrid Approaches
Rule-based systems rely on predefined logic, such as "if-else" rules, to detect specific credibility signals. These systems are particularly effective for straightforward tasks, like verifying the presence of a privacy policy or contact details on a website. For example, a rule-based model evaluating health websites achieved 97% accuracy in identifying confidentiality policies and 82% accuracy for transparency. However, its performance dropped to 51% when tasked with evaluating more complex criteria, such as financial disclosures.
To overcome these limitations, hybrid approaches combine rule-based systems with machine learning. Rule-based methods handle clear-cut metadata checks (e.g., last update date or citation presence), while machine learning models tackle nuanced tasks like detecting bias or persuasive language. This combination enhances both accuracy and interpretability.
As Adam Russell, Program Manager at DARPA, explains:
The plan is not to replace humans with machines, but rather to find the best ways to combine the two.
Hybrid systems also improve transparency. For instance, a study comparing scoring methods found that using a single rule-based measure like "Factual Density" resulted in a Mean Absolute Error (MAE) of 0.2879. When combined with a machine learning metric like "Readability Style", the MAE improved to 0.2644. Additionally, hybrid models can provide textual explanations for scores, pointing out issues like "missing citations" or "high factual density." This helps users better understand and trust the evaluation.
Russell emphasizes that "no single signal is likely to be as informative as many weak signals... if identified and correctly integrated, [they] can provide valuable new insights".
sbb-itb-f7d34da
Applications in Academic Research
Automated credibility scoring is transforming academic research by taking over the tedious process of source vetting, allowing researchers to focus more on analysis and judgment.
Streamlining Source Vetting
Manually verifying sources can be a slow and expensive task. Automated systems, on the other hand, can evaluate thousands of sources in mere minutes, far surpassing the capabilities of manual review. For example, in early 2024, researchers introduced SourceCheckup, a tool that assessed 58,000 statement-source pairs across 800 medical questions. Impressively, it achieved an 88.7% agreement rate with a panel of three US-licensed medical doctors, outperforming the typical 86.1% agreement rate seen among individual experts.
These systems also provide quick, visual summaries of credibility metrics - often referred to as "information nutrition labels." These labels highlight factors like factual accuracy, bias, and citation quality, offering researchers a clearer picture of a source's reliability. As Ivan Srba from the Kempelen Institute of Intelligent Technologies explains:
Credibility signals provide a more granular, more easily explainable and widely utilizable information in contrast to currently predominant fake news detection.
Furthermore, automated tools can process massive amounts of content - up to 128,000 tokens, roughly the length of a 200-page book - making them invaluable for tasks that would overwhelm manual efforts.
Improving Research Efficiency and Accuracy
Automated scoring not only speeds up research but also reduces human error by catching issues that might otherwise go unnoticed. Studies reveal that between 50% and 90% of AI-generated medical responses lack full source support, highlighting the importance of tools that can flag such gaps.
A notable example is the SCORE program, launched by DARPA in 2019 and later expanded with support from the Robert Wood Johnson Foundation in late 2023. This initiative analyzed 7,066 scientific claims from social-behavioral science papers, using algorithms to evaluate their replicability. Tim Errington, Senior Director of Research at the Center for Open Science, emphasized its impact:
The SCORE project is a key part of COS's mission of improving the rigor, reproducibility, and openness of research by creating scalable tools for assessing research credibility.
Similarly, Sarah Rajtmajer, an Assistant Professor at Pennsylvania State University, highlighted the progress made in recent years:
Through the last four years, we have been developing AI capable of scoring the replicability of claims in a published scholarly paper... these technologies have great potential to advance the reproducibility of research and to assess the confidence one should have in the claims generated.
Even in specialized areas, automated systems are proving their worth. For instance, a 2024 study used GPT-4o to evaluate 590 essays written by Turkish language learners. The system achieved an 83.5% overlap with professional human raters, demonstrating its reliability in academic assessment.
Integration with Research Tools
Modern research platforms are now embedding credibility scoring directly into their workflows, making these tools even more accessible. Sourcely, an AI-driven academic literature sourcing tool, is a great example. It not only identifies relevant sources but also includes credibility metrics, allowing researchers to apply filters, paste entire essays, and access millions of vetted sources - all in one streamlined process.
While automation handles tasks like identifying logical fallacies, verifying citation support, and spotting potential bias, the final judgment still rests with researchers. This collaboration between humans and machines ensures quality and accountability. For instance, an automated tool called SourceCleanup was able to revise unsupported statements so that 85.7% became properly supported by their sources after editing. This highlights how automation enhances research quality while keeping researchers in the driver’s seat.
Conclusion
The Future of Credibility Scoring in Research
Automated credibility scoring is moving toward more refined systems that use continuous scales (ranging from 0.1 to 1.0) paired with textual justifications. These future tools won't just assign a score - they’ll explain the reasoning behind each rating, giving researchers deeper insight into the quality of their sources.
Another exciting development is the rise of dynamic, agent-driven workflows. Instead of relying on static evaluations, these AI agents actively explore the web, gather additional data, and consult multiple models to refine their credibility assessments in real time. By combining signals like subjectivity detection, identification of logical fallacies, and analysis of persuasion techniques, these systems aim to provide a more nuanced and sophisticated evaluation process. This evolution promises to bring meaningful advancements to academic research.
Summary of Benefits for Researchers
These advancements translate into clear advantages for researchers. Automated credibility scoring significantly boosts both efficiency and accuracy. Tasks that once took hours - like evaluating thousands of sources - can now be completed in minutes. These systems also help catch errors or gaps that might slip through a manual review, all while offering visual credibility metrics that make the vetting process less mentally taxing.
Sourcely integrates these capabilities directly into research workflows. It automates tasks like identifying logical fallacies and verifying citations, all while keeping the researcher in control. This partnership between human expertise and AI tools enhances research integrity and allows you to produce better-quality work in less time.
FAQs
What is automated source credibility scoring, and how does it enhance research efficiency?
Automated source credibility scoring leverages sophisticated algorithms to assess the reliability of information sources both swiftly and accurately. By processing massive datasets in real time, it pinpoints dependable sources while flagging those that might be questionable. This allows researchers to make informed choices without having to manually verify every detail.
This technology is a game-changer for research efficiency. It cuts down the time spent on evaluating sources and organizing citations, enabling researchers to dedicate more energy to analysis and writing, rather than getting bogged down in the tedious task of vetting endless materials for credibility.
How do automated systems evaluate the credibility of sources?
Automated systems designed to evaluate the credibility of sources rely on AI-driven techniques to assign trust scores to content. These systems dig into factors like factual accuracy, reliability, and consistency across various sources. Here’s a closer look at some of the methods they use:
- AI language models: These sophisticated models evaluate the reliability of statements and offer explanations for the scores they assign, adding transparency to the process.
- Probabilistic analysis: By identifying patterns and reducing errors in data extraction, these models estimate how trustworthy a source is.
- Reinforcement learning: AI agents improve their credibility assessments over time by learning from real-world interactions and behaviors.
Together, these methods provide accurate, data-backed evaluations, making them incredibly useful for tasks like academic research and information gathering. Tools such as Sourcely use these approaches to help researchers efficiently find credible academic resources.
How do automated systems evaluate and ensure the reliability of credibility scores?
Automated systems calculate credibility scores by using AI models trained on datasets that have been thoroughly reviewed and verified by humans. These models sift through data to assess accuracy, consistency, and relevance, often incorporating fact-checking techniques to verify claims and sources.
To maintain reliability, these systems regularly compare their results with expert evaluations. They also use statistical tools like mean absolute error (MAE) and R² to track performance. Frequent updates and adjustments help improve their precision, ensuring they stay closely aligned with human assessments.
