
Metadata Crosswalks: Standards and Frameworks
Metadata crosswalks are essential for connecting different metadata schemas, ensuring data can be shared and understood across systems. They involve mapping elements from one schema to another and creating a visual representation of these mappings. This process is crucial for improving discovery of relevant research sources, interoperability, and compliance with standards like the FAIR principles.
Key frameworks include:
- Schema.org Crosswalks: Useful for web discovery and search engine visibility but may lose detailed metadata during mapping.
- DCAT-AP: Designed for European data portals, supporting semantic and technical interoperability, though it struggles with granularity.
- MSCR: A registry for managing metadata schemas and crosswalks, offering automation and versioning but requiring user authentication.
- DESM: Uses a synthetic spine for semantic mappings, ideal for aligning standards but less effective for technical transformations.
- OAI-PMH: Focuses on repository-level metadata harvesting, offering scalability but with potential data loss when converting to simpler schemas like Dublin Core.
Each framework serves different needs, from enhancing web visibility to managing complex metadata workflows. Choosing the right one depends on your goals, whether it's improving discoverability, standardizing data, or ensuring seamless data sharing.
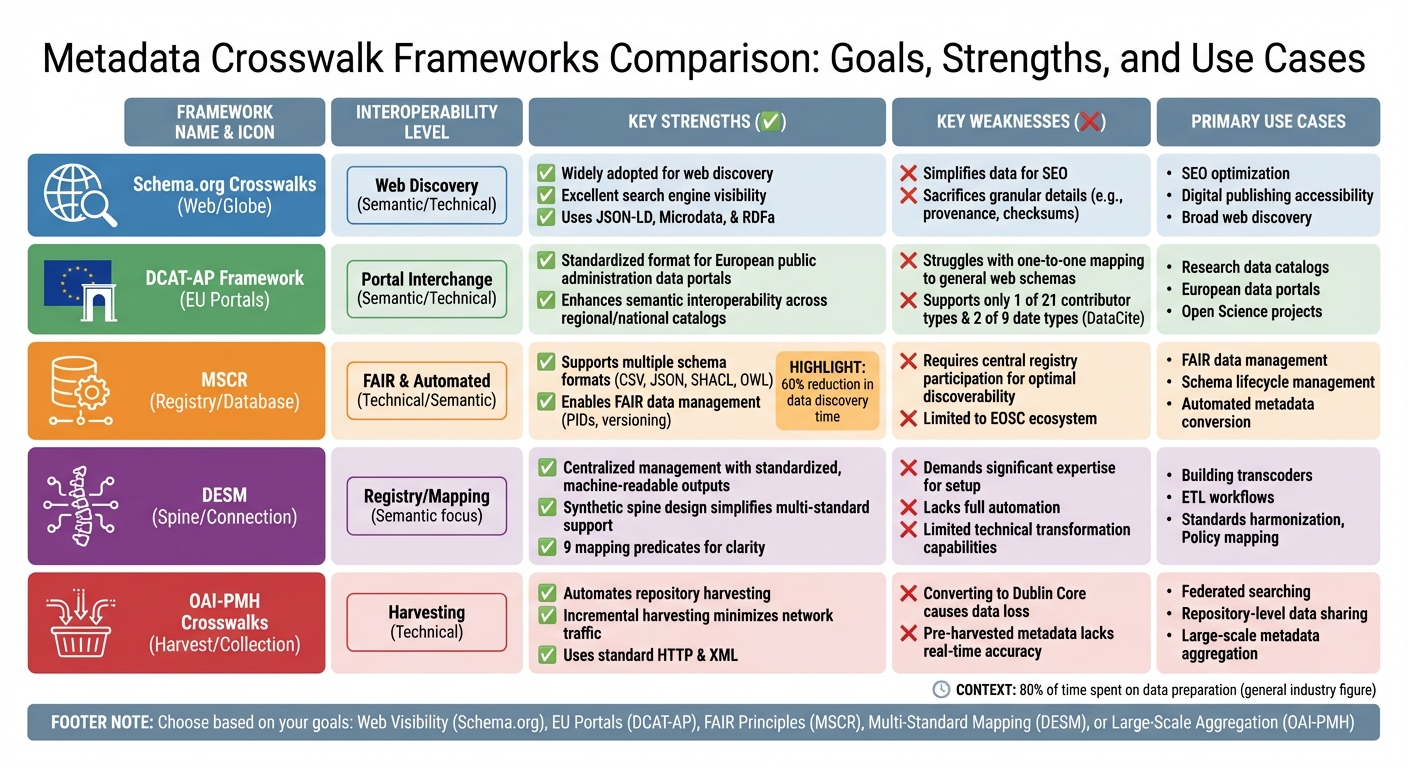
Metadata Crosswalk Frameworks Comparison: Features, Strengths and Use Cases
Session 7: Utilizing Frameworks, Platforms, and Community Roadmaps to Promote Reproducibility
sbb-itb-f7d34da
1. Schema.org Crosswalks
Schema.org crosswalks bring structure to metadata through three abstraction levels: an abstract layer with human-readable documents referencing standards like Dublin Core and MARC21, a version-specific layer tied to specific XML schema versions, and a concrete layer using machine-processable encodings like XSLT. These layers form the foundation for both the strengths and challenges of this approach.
Strengths
Schema.org crosswalks enhance how data is discovered online. By embedding markup, research data managers make it easier for search engines and tools like Google Dataset Search to locate datasets. A great example is the CodeMeta project, which uses Schema.org terms as a shared vocabulary to translate metadata between platforms like GitHub, Zenodo, and DataCite. Another advantage is its broad compatibility - Schema.org crosswalks already connect with standards like DCAT, DataCite, ISO 19115, and MARC.
Weaknesses
One major drawback is the potential for data loss during conversion. Complex schemas, such as MARC with its six unique title fields (e.g., 210, 222, 240, 242, 245, and 246), often lose their granularity when mapped to simpler formats like Schema.org or Dublin Core. Metadata expert Karen Coyle highlights this challenge:
"The more metadata experience we have, the more it becomes clear that metadata perfection is not attainable, and anyone who attempts it will be sorely disappointed".
Another issue is that crosswalks are generally one-way. Mapping from Schema A to Schema B and then back again often requires separate conversions, which can result in incomplete restoration of the original data.
Use Cases
Libraries frequently use Schema.org crosswalks to convert MARC records into formats suitable for the web. Research data registries also rely on them to process non-standard XML or JSON-LD records, using tools like XSLT to transform these into common exchange formats such as RIF-CS. Additionally, the Research Data Alliance has developed a master crosswalk that maps Schema.org properties to over 10 major metadata standards, enabling seamless integration of data from platforms like Dataverse, Figshare, and Dryad.
2. DCAT-AP Framework
The DCAT Application Profile for data portals (DCAT-AP) is a specification based on the W3C Data Catalogue vocabulary. It was created to describe public sector datasets across Europe. First introduced in September 2013, DCAT-AP has grown to include extensions like GeoDCAT-AP and StatDCAT-AP. The upcoming version 3.0.0, set for release in June 2024, aligns with W3C DCAT 3 and brings new features, such as support for "Dataset Series". This growth reflects its multi-layered approach to interoperability, which is detailed below.
Interoperability Levels
DCAT-AP supports four key levels of interoperability:
- Technical: Ensures systems can process RDF exports and imports.
- Semantic: Employs controlled vocabularies like EuroVoc and NAL to establish shared meanings across platforms.
- Organizational: Enables data exchange among Open Data Portals of EU Member States and institutions.
- Legal: Includes metadata for "applicable legislation" to clarify the legal basis for data access.
These levels work together to provide a cohesive framework for data sharing across borders and sectors.
Strengths
The framework simplifies data sharing across EU data portals, making cross-border and cross-sector searches more efficient. Built on RDF and Linked Data principles, DCAT-AP integrates well with Semantic Web tools and automated harvesting systems. Its flexibility allows for domain-specific adaptations while maintaining a standardized core. For instance, HealthDCAT-AP serves as the standard for the HealthData@EU infrastructure. The European Commission highlights its value:
"The availability of the information in a machine-readable format as well as a thin layer of commonly agreed metadata could facilitate data cross-reference and interoperability and therefore considerably enhance its value for reuse".
Weaknesses
Despite its benefits, DCAT-AP has limitations. It struggles with granularity issues when compared to domain-specific standards. For example, it supports only 1 of 21 contributor types and 2 of 9 date types defined by DataCite. Structural differences also pose challenges; DCAT-AP treats "Size" and "Format" as properties of a distribution, while other schemas like DataCite associate them with the dataset. Additionally, it lacks key elements like "Funding Reference". Converting DCAT-AP metadata to more general schemas, such as Schema.org, often results in data loss.
Use Cases
Despite its challenges, DCAT-AP is widely used in European data initiatives. It helps European data portals enable users to locate datasets across Member States, even when dealing with language differences or unfamiliar administrative structures. Research institutions use CiteDCAT-AP to share DataCite-registered scientific datasets through broader European data catalogues. Organizations also convert DCAT-AP records into Schema.org format to improve visibility on major search engines. To ensure compliance, tools like the Interoperability Testbed and SHACL templates validate catalogues against DCAT-AP standards.
3. MSCR (Metadata Schema and Crosswalk Registry)
The Metadata Schema and Crosswalk Registry (MSCR) is a centralized system developed as part of FAIRCORE4EOSC to streamline research data management within the European Open Science Cloud. It allows users to create, share, and manage versioned metadata schemas and crosswalks, all linked to resolvable PIDs like DOIs or Handles. The final version is expected by Q2 2025. Unlike one-off, undocumented scripts, MSCR offers a structured framework where crosswalks can be cited and easily discovered. This system not only documents the mappings but also makes them usable through automated workflows.
A major issue in research data management is the time spent preparing data rather than analyzing it - data professionals reportedly spend up to 80% of their time on these tasks. By adopting mature metadata frameworks, organizations can cut data discovery time by 60%. MSCR directly addresses this by offering a registry for storing schemas and crosswalks, along with a visual Crosswalk Editor that simplifies mapping between metadata schemas without requiring advanced coding skills.
Interoperability Levels
MSCR supports both semantic and technical interoperability. On the semantic side, it integrates with tools like the Data Type Registry (DTR) and Vocabulary Services, enabling consistent attribute definitions across platforms. Technically, it provides an API and generates executable transformation scripts - such as XSLT and RML - for automated metadata conversion. This combination ensures that crosswalks aren't just theoretical but can be immediately applied for metadata transformation.
Strengths
MSCR supports a wide variety of formats. For metadata schemas, it accommodates CSV, XSD, JSON Schema, RDFS, SHACL, OWL, SKOS, ENUM, and even PDF files. For crosswalks, it works with formats like SSSOM, Simple Table, XSLT, and PDF. The visual Crosswalk Editor, although more limited, supports JSON, CSV, XSD, SHACL, and SKOSRDF formats. FAIRCORE4EOSC highlights this capability:
"The MSCR facilitates interoperability between information systems on a semantic and technical level through discoverable, accessible and actionable schemas and crosswalks".
Another key advantage is its versioning system for schemas and crosswalks, which helps researchers adapt to evolving software requirements or metadata standards. The API automates metadata transformation during repository harvesting. Additionally, researchers can assign DOIs to their custom conversion scripts, making it easier to cite the exact version of a crosswalk used in a study or Data Management Plan (DMP).
Weaknesses
Despite its robust features, MSCR has some limitations. The visual Crosswalk Editor doesn’t support all the formats that the registry can handle - formats like PDF and OWL can be stored in the registry but aren’t usable within the editor. Its integration with EOSC-Core services, such as B2Access for authentication and the Data Type Registry, may limit its appeal to users outside the European Open Science Cloud ecosystem. Furthermore, while browsing and downloading content is open to all, creating or registering content requires user authentication and registration.
Use Cases
MSCR shines in situations where teams need to harmonize metadata from various repositories into a unified schema for specific software. The EOSC Association elaborates:
"The EOSC Metadata Schema and Crosswalk Registry (MSCR) provides the steps to translate data from different repositories with non-compatible metadata schemas to a single metadata schema to enable data analysis".
Research institutions rely on MSCR to manage multiple crosswalk versions, ensuring that teams using different software versions can work with the correct mappings. By making mapping scripts discoverable and reusable, the registry supports FAIR principles and reduces reliance on undocumented, project-specific scripts. Organizations can also integrate the MSCR API into their data pipelines, automating metadata translation and standardizing workflows.
4. DESM (Data Ecosystem Schema Mapper)
The Data Ecosystem Schema Mapper (DESM) is an open-source tool created through the U.S. Chamber of Commerce Foundation's T3 Innovation Network program. It operates under an Apache 2.0 license and utilizes a "synthetic spine" - a schema-neutral reference point that grows as new properties are identified. Instead of directly linking every pair of standards, DESM connects each standard to this central spine, enabling indirect, transitive mappings.
Credential Engine's CTDL team transitioned from spreadsheet-based crosswalks to DESM, which improved both transparency and machine-readability. The tool supports schema uploads in various formats, including JSON-Schema, RDF (JSON-LD, Turtle, RDF/XML), XML XSD, and standardized CSV templates. Notable implementations include:
- The QualityLink Project, deployed by the Knowledge Innovation Centre with European Commission funding.
- The IEEE Competency Data Standard, which used DESM for baseline mapping to identify overlaps and gaps.
- Advanced Distributed Learning (ADL), which applied DESM mappings to inform the Total Learning Architecture specification.
Interoperability Levels
DESM addresses two distinct levels of interoperability: intellectual mapping and technical mapping. As Credential Engine explains:
"The DESM tool currently focuses primarily on intellectual mapping with some limited attention to noting technical mapping issues".
- Intellectual mapping focuses on comparing attribute definitions, extensions, and value space definitions across different metadata schemas. This process ensures semantic alignment between standards.
- Technical mapping, on the other hand, deals with syntactic and structural challenges, such as one-to-many field transformations. DESM, being format-agnostic, prioritizes the semantic meaning of properties over their technical representation.
Strengths
DESM’s synthetic spine design simplifies the process of supporting multiple standards without requiring complex pairwise mappings. As new, unmapped properties are identified, the spine evolves to accommodate them. The tool offers nine mapping predicates - such as Identical, Reworded, Similar, Sub-property Of, and No Match - to clearly define relationships between terms. This structured approach enhances clarity and generates machine-actionable JSON-LD output for developers. Additionally, it supports gap analysis, helping organizations identify areas where their specifications may fall short compared to others.
Weaknesses
While DESM excels in semantic mapping, it demands significant expertise for initial setup and lacks full automation. Its limited capability to handle complex technical transformations, such as many-to-one conversions, means additional tools are often required for structural interoperability. The tool works best when an iterative process is followed, with regular collaboration among experts in different data models - a process that can be resource-intensive.
Use Cases
DESM is highly versatile and serves several practical purposes:
- Building transcoders: Facilitates translation of data between standard formats.
- ETL workflows: Identifies terms that require transformation during Extract, Transform, Load processes.
- Standards harmonization: Bridges gaps across fragmented sectors like education and employment.
- Policy mapping: Ensures standards align with legal and organizational compliance requirements.
Its ability to handle multiple standards simultaneously makes it particularly useful for research institutions managing diverse metadata across various systems. DESM plays a key role in interoperability efforts, simplifying multi-standard mappings and complementing other interoperability tools.
5. OAI-PMH Crosswalks

The Open Archives Initiative Protocol for Metadata Harvesting (OAI-PMH) operates at a broader repository level rather than focusing on individual schema mappings. Introduced in June 2002, version 2.0 established a framework where repositories share metadata using a standardized protocol, while harvesters collect this data to create searchable databases. This system relies on two main players - Data Providers (repositories sharing metadata) and Service Providers (harvesters collecting and aggregating metadata). Unlike more detailed schema-specific mappings, OAI-PMH focuses on repository-level aggregation, complementing the finer crosswalk methods discussed earlier.
To ensure interoperability, OAI-PMH requires all compliant repositories to support unqualified Dublin Core as a baseline metadata format. Additionally, repositories can offer metadata in multiple formats like MARC, MODS, or RIF-CS. This flexibility allows metadata to be converted from its original form within the repository, enabling selective harvesting based on criteria such as datestamps for updates or grouping records into "Sets".
Strengths
One of OAI-PMH's standout features is its incremental harvesting capability, which minimizes network traffic by collecting only records that have been created or modified within a specific time period. Its use of standard HTTP and XML ensures compatibility across platforms without requiring specialized software. For instance, NASA's Mercury metadata search system leveraged OAI-PMH to index thousands of metadata records daily from the Global Change Master Directory (GCMD), showcasing its scalability for large-scale data sharing. Similarly, the National Science Digital Library (NSDL) Metadata Repository utilized the protocol to automate the ingestion of fragmented metadata - such as converting Alexandria Digital Library (ADL) records into Dublin Core format - resulting in more complete resource profiles.
"The OAI-PMH provides an application-independent interoperability framework based on metadata harvesting".
This straightforward approach has made OAI-PMH widely popular in academic and digital library settings.
Weaknesses
However, converting metadata to Dublin Core can result in the loss of details found in richer schemas, with specific subfields becoming ambiguous or entirely missing, which can affect data quality. Aggregated metadata may also suffer from incomplete elements, non-standardized values, or a lack of controlled vocabularies. Additionally, because OAI-PMH relies on pre-harvested metadata rather than real-time collection, it prioritizes speed over up-to-the-minute accuracy.
Use Cases
Despite its limitations, OAI-PMH has proven useful for large-scale metadata aggregation. For example, in 2004, Yahoo! integrated metadata from the OAIster service at the University of Michigan, which harvested records from various digital archives to enhance its search engine. Wikimedia also utilizes an OAI-PMH repository to provide update feeds for Wikipedia and related projects, making it easier for search engines and bulk analysis tools to republish or analyze content efficiently.
The protocol is particularly effective for building centralized discovery systems, maintaining union catalogs, and enabling resource sharing across institutions.
"metadata aggregators provide enhanced metadata for other services to reuse, including the following: integrating fragmentary metadata created by automated services".
For research institutions managing metadata from multiple repositories, OAI-PMH offers a standardized method to collect, normalize, and share diverse records through a unified interface. This supports the broader goal of creating interoperable metadata systems with consistent conversion standards. For more insights on optimizing academic workflows, explore our research and citation blog.
Comparison Table
Here's a quick side-by-side look at the five frameworks, highlighting their interoperability, strengths, weaknesses, and best use cases.
| Framework | Interoperability Level | Key Strengths | Key Weaknesses | Primary Use Cases |
|---|---|---|---|---|
| Schema.org Crosswalks | Web Discovery (Semantic/Technical) | Widely adopted for web discovery; excellent search engine visibility with JSON-LD, Microdata, and RDFa | Simplifies data for SEO but sacrifices granular details like provenance or checksums | SEO optimization, digital publishing accessibility, broad web discovery |
| DCAT-AP Framework | Portal Interchange (Semantic/Technical) | Standardized format for European public administration data portals; enhances semantic interoperability across regional and national catalogs | Struggles with consistent one-to-one mapping to general web schemas | Research data catalogs, European data portals, Open Science projects |
| MSCR | FAIR & Automated (Technical/Semantic) | Supports multiple schema formats (e.g., CSV, JSON Schema, SHACL, OWL); enables FAIR data management with persistent identifiers (PIDs) and versioning | Requires participation in a central registry for optimal discoverability | FAIR data management, schema lifecycle management, automated metadata conversion |
| DESM | Registry/Mapping | Centralized management with standardized, machine-readable outputs; supports versioning and validation | Relies on strong community maintenance and endorsement | Metadata conversion automation, mapping lifecycle management in repositories |
| OAI-PMH Crosswalks | Harvesting (Technical) | Automates repository harvesting; integrates diverse files and metadata for seamless exchange | XSLT-based transforms may lose semantic details during structural changes; converting to Dublin Core often reduces schema richness | Federated searching, repository-level data sharing, large-scale metadata aggregation |
Each framework serves different needs. Web standards like Schema.org are ideal for broad visibility, while registry-based tools like DESM focus on precision and detailed management. For researchers handling intricate datasets, it's all about finding the right balance between discoverability and detail.
As Juha Hakala, Director of IT at the National Library of Finland, puts it:
"Crosswalks merely represent a 'proof of concept'. Right now, they need to be augmented with robust systems that handle validation, enhancement, and multiple character encodings".
Conclusion
When deciding on a metadata crosswalk framework, the choice ultimately hinges on your specific goals and requirements. For example, if your focus is on boosting web visibility and search engine optimization, Schema.org is an excellent option due to its ability to enhance discoverability. On the other hand, if you're working within European data portals or Open Science initiatives, DCAT-AP provides the structured standardization you need.
That said, no framework is flawless. Converting between schemas - especially from highly detailed ones like MARC to simpler formats such as Dublin Core - often leads to a loss of granularity. Creating effective crosswalks demands significant resources and expertise in both the source and target schemas.
To streamline the process, start with intellectual mapping to plan your approach, then automate using executable code like XSLT . As the LD4PE guidance advises:
"To create a technical mapping, programmers and developers should use this crosswalk for general guidance, but please refer to the original standards".
For implementation, consider a hub-and-spoke model, such as the one employed by CodeMeta. This method uses a central set of properties to simplify mappings, avoiding the need for direct connections between every pair of standards. Tools like Sourcely (https://sourcely.net) can also be invaluable for researchers managing citations and literature across various metadata standards, helping to organize and align sources with your chosen framework efficiently.
FAQs
How do I choose the right crosswalk framework for my project?
To pick the best crosswalk framework for your needs, start by identifying your metadata standards and clearly outlining your goals. Next, examine existing crosswalks that align with your specific domain - this can save time and provide valuable insights. Consider the scope and complexity of your project to ensure the framework can handle your requirements.
It's also crucial to verify that the framework is flexible, easy to maintain, and works well with your current tools and file formats. By carefully evaluating these factors, you'll be able to choose a crosswalk framework that ensures smooth metadata interoperability for your project.
How can I reduce metadata loss when converting between schemas?
To reduce metadata loss during schema conversion, it's crucial to develop detailed crosswalks that carefully map elements between different schemas. Pay close attention to aligning similar elements, and make sure to document any assumptions you make along the way. For elements that are optional or particularly complex, provide explicit mapping details to avoid confusion.
In addition, use both machine-readable and human-readable descriptions to make the process clearer for everyone involved. When direct equivalents between schemas aren't available, create custom mappings to fill in the gaps. This approach helps maintain metadata integrity throughout the entire conversion process.
When should I use OAI-PMH instead of schema-to-schema crosswalks?
When you need to gather and share metadata from multiple repositories in a standardized format, OAI-PMH (Open Archives Initiative Protocol for Metadata Harvesting) is the way to go. It streamlines the process of aggregating metadata, even in varied and complex environments, without the hassle of manual schema conversions.
On the other hand, schema-to-schema crosswalks are ideal for directly mapping metadata between specific schemas. These are particularly useful when working within controlled systems that demand precise data integration or compatibility. While they require a deep understanding of the schemas involved, they ensure accurate and reliable interoperability.
